Avoiding Common Errors & Challenges in Implementing 3D Vision in Industrial Manufacturing Automation
Deploying 3D vision systems in industrial manufacturing automation can significantly enhance efficiency. However, the path from concept to successful implementation is full of challenges.
Deploying 3D vision systems in industrial manufacturing automation can significantly enhance flexibility, precision, and efficiency. However, the path from concept to successful implementation is full of challenges. According to Gartner, only 53% of vision projects advance from prototype to production.
This article explores the challenges faced, and provides practical solutions to help you successfully navigate the deployment of these 3D vision systems in industrial settings.
#1. Altogether Neglecting Robot Vision Integration
One of the fundamental errors in automation projects is not setting up robots with vision capabilities at all. While vision systems aren’t needed for all automation tasks, they do allow robots to make decisions based on visual data, which is crucial for tasks requiring unpredictable scenarios, scanning environments, or inspection. Robots without vision are confined to their pre-programmed paths and tasks, and are unable to adapt to changes in their environment.
Without vision systems, a significant amount of data goes unutilized, leading to missed opportunities for optimization. Integrating a vision system enables robots to adapt and respond to dynamic conditions. Not only that, but they can also be used for quality control and defect detection, improving product reliability and reducing waste over time.
#2. Misunderstanding Vision System Limitations
2D Vision Systems
2D vision systems rely heavily on lighting conditions, making them prone to errors in varying light environments. 2D systems’ other limit is that they cannot capture depth information, which is crucial for many industrial applications. While it’s possible to implement consistent lighting conditions in the workspace to minimize errors, it might be easier to use 3D vision systems.
3D Vision Systems
3D vision systems have become integral in a variety of applications, particularly in industrial and robotic settings, due to their ability to provide spatial data and depth perception (important for tasks like robotic manipulation, navigation, complex assembly, etc). Typically using infrared technology, these systems can overcome some lighting issues but have their own set of limitations: factors like reflective surfaces (light bouncing in unpredictable ways), plane surfaces, transparent surfaces (the materials might not reflect the necessary signals back to the sensors), can affect their performance. 3D vision systems also require a precise calibration to ensure the accuracy of depth and spatial data, which can be time-consuming and complex to set up initially.
In order to avoid such issues, it’s possible to implement systems that can recalibrate automatically and in real-time to adapt to changes in the setup or the environment. It’s also possible (and recommended) to implement online learning where the model continuously learns and updates itself from new data gathered during operation. This is particularly useful in environments where conditions change frequently, or where the system encounters new objects and scenarios. These optimizations will allow the 3D vision system to perform in a more intelligent and adaptable manner in industrial environments.
#3. Hardware Limitations
Choosing the wrong camera type for the task (RGB, depth, infrared, stereo) or having inappropriate camera resolution, frame rate, field of view, or calibration can hinder the performance of vision systems, which is why it’s important to match the camera specifications to the specific needs of the application.
Selecting the appropriate hardware is fundamental to the success of a vision system. Choosing the wrong camera type or specifications can limit system performances, and poor integration between hardware components can lead to system inefficiencies.
#4. Improper Vision Sensor Setup
The placement of vision sensors is crucial for optimal performance. The two main configurations are:
Eye-in-Hand
Cameras attached to the robot’s end-effectors (typically its hands or arms) offer a flexible view but are limited by their field of view, restricted to the robot’s immediate vicinity. This is the setup that inbolt has decided to go with.
This setup has several significant advantages:
- Placing the camera on the robot’s end-effectors allows for very close and detailed inspections of objects and environments.
- As the robot manipulates or interacts with objects, the camera can adjust its viewpoint dynamically.
- This configuration enhances the robot’s ability to perform complex tasks that require visual feedback, like precise positioning, inserting a component or welding, etc. The camera provides real-time feedback to adjust the robot’s actions based on what it sees.
However, there are some limitations to this setup:
- The camera’s view is generally limited to what is immediately in front of the robot’s end-effector. This means it may not be able to see other parts of the environment that could be relevant to the task.
- Since the camera is attached to the robot, its movement is inherently tied to the movements of the robot itself. This can limit the camera’s utility in scenarios where a broader or different perspective is needed without moving the entire robot.

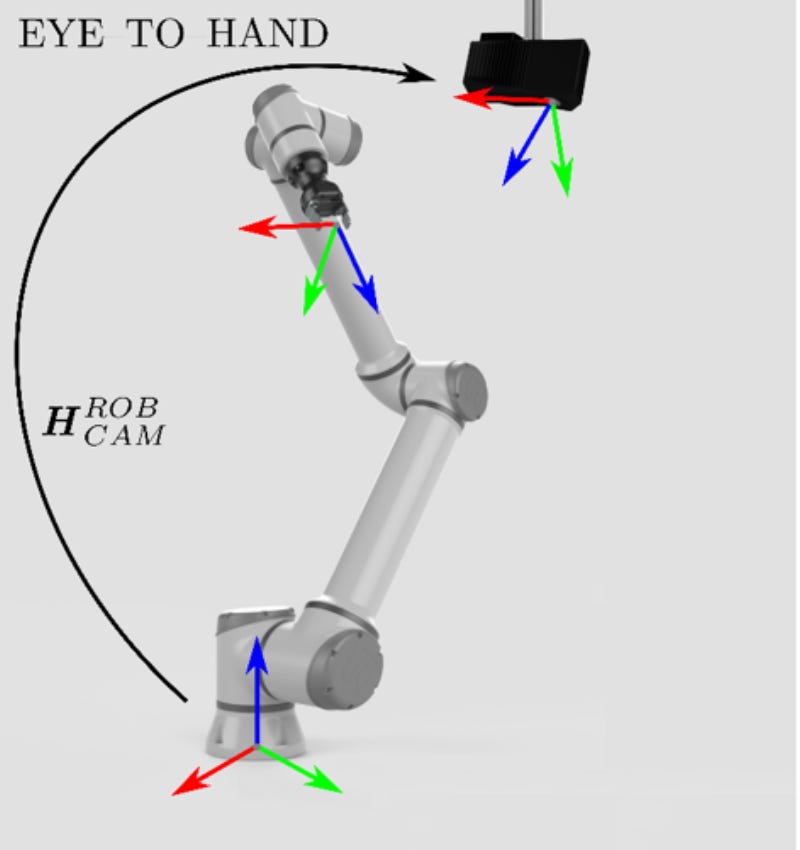
Eye-to-Hand
The Eye-to-Hand configuration in robotic systems is another approach where cameras are mounted in a fixed position relative to the robot, but not on the robot’s end-effectors. Instead, the cameras are positioned to overlook the workspace or the area where the robot operates. This setup offers a different set of advantages compared to the Eye-in-Hand configuration:
- Since the cameras are not limited to the perspective of the robot’s end-effectors, they can provide a wider view of the entire work area. This is beneficial for tasks that require monitoring or interaction over a larger space.
- They can offer more stable and less jittery images, since they are not subject to the movements of the robot.
- They can oversee the activities of multiple robots working in the same area.
But, they also have their limits:
- These setups sometimes struggle with capturing fine details, since the cameras are not close to the action.
- The feedback loop can be less direct, and adjustments based on visual feedback might not be as immediate or precise.
#5. Poor Data Quality
High-quality, well-annotated data is essential for training effective vision models, as it helps the model recognize and interact with various objects and scenarios it will encounter in real-world operations.
Poor data quality (that does not represent the full spectrum of potential scenarios), particularly in robotics, can affect the performance of these systems by degrading model performance and leading to unreliable results (object recognition, faulty decision-making, inefficient robotic behavior). For example, a robotic vision system trained predominantly on images from well-lit environments might not be as efficient in dim conditions.
Some solutions to improve this issue are:
- Data augmentation (rotation, scaling, flipping) techniques, which can help in creating a more robust dataset by presenting the same object in different orientations, sizes and perspectives, training the model to recognize objects regardless of how they appear in the field of vision of the robot.
- Adjusting brightness, contrast, and color saturation, helping the model perform consistently across different lighting conditions.
- Continuously testing the model in real-world conditions and feeding back the performance data into the training cycle to refine and improve the model.
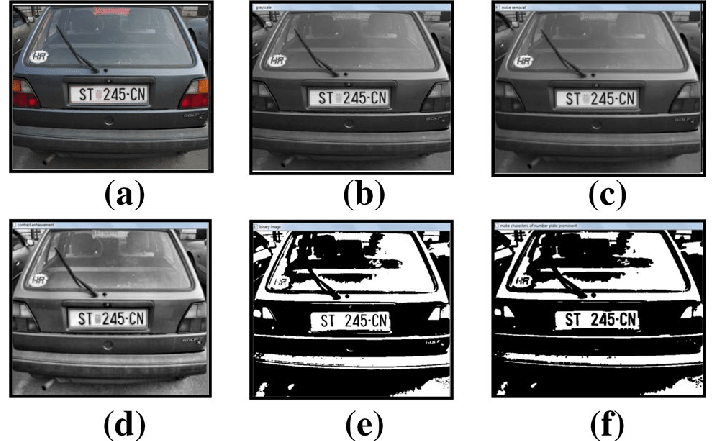
#6. Inadequate Image Preprocessing
Effective preprocessing of images—through cropping, resizing, rotating, filtering, enhancing, or normalizing—removes noise, correct distortions, and highlights relevant information. Poor preprocessing can lead to models that will not be able perform well. If each image is preprocessed differently, the variability can lead to inconsistencies and poor model performance. Excessive preprocessing sometimes removes essential features from images, while insufficient preprocessing sometimes leaves in noise and irrelevant data, making it harder for the model to learn to identify what is important.
To fix these challenges, developing and implementing a standardized set of preprocessing steps for all images, tailored to the needs of the specific application, is a good start. Applying filters to reduce noise or enhance features is a good idea, as well as more complex augmentations like random cropping, zooming, or geometric transformations, in order to make the model more robust to scales and orientations.
Once this has been done, one can set up algorithms to automatically check the quality of these preprocessed images, and monitor the performance over time. If certain preprocessing techniques consistently lead to poor model performance, they may need to be adjusted or replaced.
#7. Incorrect Algorithm and Model Selection
Selecting the right algorithms for the success of a vision system matters, as each task will require a specific model—depending on the complexity of the data, computational resources, desired accuracy, speed, etc. Using a one-size-fits-all approach can result in issues, like overfitting (using a complex models for simple tasks, resulting in a model that performs well on training data but poorly on unseen data), underfitting (using a simple model that can prevent the system from learning the patterns effectively, leading to poor overall performance), or inefficiency (using a model not optimized for the available computational resources, leading to slow response times and high power consumption).
To avoid this problem, conduct an analysis of the specific tasks, and select the model accordingly: define the vision task; assess the complexity of the data involved, the computational resources available (processing power, memory, energy constraints); consider the trade-offs between model complexity and performance. Finally, test multiple models to compare their performance in terms of accuracy, speed, and resource utilization on relevant tasks, before making your final decision.
The Word of The End
Deploying 3D vision systems in industrial manufacturing automation requires the navigation of a myriad of potential errors and challenges. By understanding and addressing these common challenges, manufacturers can avoid the pitfalls and improve the success rate of their projects.
Other challenges remain after that, of course, like the ability of the vision system to communicate with existing data management, or the training of employees (not only on how to operate the new systems, but also on how to interpret the data they provide).
The implementation of a 3D vision system needs to include these integration aspects, which improves their practical usability in real-world industrial settings, allowing companies to fully leverage advanced vision technologies. Afterwards, staying updated is the best way to get to know more models and techniques that could improve the performance.
Explore more from Inbolt
Access similar articles, use cases, and resources to see how Inbolt drives intelligent automation worldwide.
Why real-time robot control is the key to unlocking Physical AI

What bin picking really means in production: from semi-structured to unstructured environments

Why the future of automation is being written by the automotive industry

Reliable 3D Tracking in Any Lighting Condition

The Circular Factory - How Physical AI Is Enabling Sustainable Manufacturing

NVIDIA & UR join forces with Inbolt for intelligent automation

KUKA robots just got eyes: Inbolt integration is here


